3,917 views
 Monitoring Robocopy logfiles with Operations Manager 2007 (vbscript monitor)
Monitoring Robocopy logfiles with Operations Manager 2007 (vbscript monitor)
One of the reasons why the company I work at has taken the decision to implement Operations Manager is because the daily task to go through a pile of interfacing and backup log files became too time consuming and demotivating for the people involved. Armed with Operations Manager and a basic vbscript, I have set up a couple of monitors that now have automated the entire process.
These are the components that I have set up in order to get it to work :
- I created a vbscript that parses to one or more robocopy log files. The only real limitation of the script in its current form is that it only goes through the first set of robocopy output in the log file. So if you have the habit to append the output of multiple robocopy scripts, or multiple instances of the same script into the same log file, you’ll either have to change the script, or you’ll have to change your robocopy scripts.
- Define what you want to monitor : what is the log file name, file location. Are you satisfied with the way the script will determine whether the log file is healthy or not (see later) ? Determine the right time to check the log file (don’t check the log file at a time when you know the robocopy script is still writing in the file), etc.
- I created a monitor that uses the script and uses data that is passed back from the vbscript to OpsMgr to determine whether a log file (and the corresponding robocopy process) can be considered healthy or not.
- I set up alerting, including some data about the log file(s) in the alert description field.
The script
You can download the latest copy of the script from here :
These are the most important pieces
-
The script checks if you have provided at least one parameter. If not, an event will be logged in the event log and the script will quit.
This is what the event will look like :

- Every parameter stands for a log file. You can specify any number of log files (well, "any" may be to broad … I’m sure OpsMgr has some limitations, but I ran one script against up to 10 log files, without problems). Ideally, I would recommend using separate monitors for log files that are not related to other log files. It’s a bit of work to set up, but once it is set up, you’ll never need to touch your monitor config again. Note : you cannot use wildcards for specifying the log files. You can either modify the script to accept wildcards, or you should specify all of the log files individually as parameters to the script.
-
Each log file is opened, the header of the robocopy log file is skipped, and the log file is read all the way until it finds the footer (the set of data that contains the information about the number of files, dirs and bytes that have been copied, skipped, failed, and so on. This information is parsed from the log file and stored in unique variables. Because the script allows you to process multiple log files, a sequence number is appended to each of these variables. So the variables that related to the first log file, will be appended with number 1 (as parameter name). These are the most important variables :
-
For each log file : 23 variables
- Logfilefoundx (where x = sequence number of the log file) (true or false)
- Finishedx (true or false)
- NrOfDaysAgox (numeric) (set to -1 if file was not found)
- TotalNrOfBytesx (string)
- TotalNrOfDirsx (numeric)
- TotalNrOfFilesx (numeric)
- NrOfCopiedBytesx (string)
- NrOfCopiedDirsx (numeric)
- NrOfCopiedFilesx (numeric)
- NrOfSkippedBytesx (string)
- NrOfSkippedDirsx (numeric)
- NrOfSkippedFilesx (numeric)
- NrOfMismatchBytesx (string)
- NrOfMismatchDirsx (numeric)
- NrOfMismatchFilesx (numeric)
- NrOfFailedBytesx (string)
- NrOfFailedFilesx (numeric)
- NrOfFailedDirsx (numeric)
- NrOfExtraBytesx (string)
- NrOfExtraDirsx (numeric)
- NrOfExtraFilesx (numeric)
- LogFileNamex (string)
-
LastRunTimex (string)
-
General data (for all of the log files)
- TotalFailedDirs (numeric)
- TotalFailedFiles (numeric)
- AllLogFilesFound (true or false)
- AllFinished (true or false)
- FailedLogs (string)
-
Information (string containing some detailed information about all of the log files. Useful in alert description fields.
-
-
A logfile is considered to be a "failed" logfile if
- It contains failed files
- It contains failed dirs
- It is older than 3 days (hardcoded in the script – change this value to whatever you want)
- It cannot be found
- It does not contain the footer (so it has not completed yet)
If you want different behavior, you’ll have to change the logic in the script.
- After processing all log files, the property bag is sent back to OpsMgr. If you only monitor 1 log file, 27 parameters will be passed back. You can use any of these 27 parameters in the expression or in the alert description, giving you maximum flexibility

Operations Manager configuration : set up the monitor
Log file : c:\robocopy.log
Open authoring, go the monitoring, and set the scope to "Windows Server 2003 computer" (or any other group that contains computer objects)
Open "Entity Health" – "Availability", right click and choose "Create a monitor". Select "Unit Monitor"

Select "Scripting" – "Generic" – Timed Script Two State Monitor, and select a custom management pack
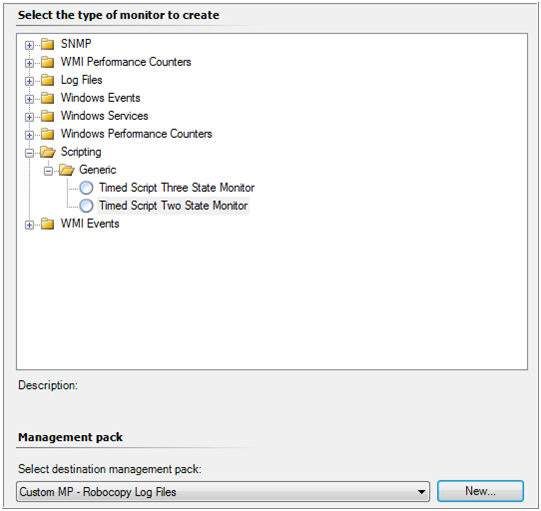
Specify a good name for your monitor, verify that the target is set to Windows Server 2003 computer (or any other target containing computer objects) and make sure the monitor is disabled

Configure the schedule. I’ll set the script to run every 15 minutes, for testing purposes

Define the script filename (don’t forget the .vbs extension) and set a timeout.
Paste the entire script (see above) in the Script: field

Click the "parameters" field and fill out the full path to the log file(s). Put the path between double quotes, and separate multiple logfiles with a space.

Set the unhealthy expression. I’ll use a more or less generic trap : if the variable "FailedLogs" contains a dot (.), then it contains a reference to at least one log file, so the monitor should go into unhealthy state.
This is how you should reference a variable in the expression : Property[@Name=’FailedLogs’]
My unhealthy expression looks like this :

The healthy expression looks like this :

Choose the health state
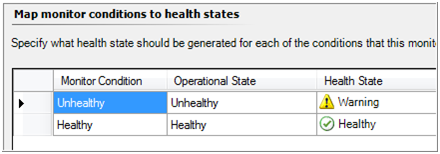
Set alert settings :

If you are only monitoring one log file with this monitor, you can get some of the individual log file variables :
Logfile name : $Data/Context/Property[@Name=’LogFileName1′]$
Log file found : $Data/Context/Property[@Name=’LogFileFound1′]$
Log file finished : $Data/Context/Property[@Name=’Finished1′]$
Age of logfile (in days) : $Data/Context/Property[@Name=’NrOfDaysAgo1′]$
Nr of failed file copy actions logged : $Data/Context/Property[@Name=’NrOfFailedFiles1′]$
Nr of failed dir copy actions logged : $Data/Context/Property[@Name=’NrOfFailedDirs1′]$
If you have more than one logfile, you can use $Data/Context/Property[@Name=’Information’]$
The number of variables that can be used in the alert description field is limited to 10 (OpsMgr limitation), so if you are monitoring multiple log files, I’d recommend only using some of the general variables and not individual log file variables.
Save the monitor
Create an override and set the monitor to run on the server that hosts the log file.



Save the override
Wait until the Management Pack gets distributed and the script kicks in.

Have a look at the event log. You should see 2 Health Service Events (under Operations Manager) with Event ID 101, indicating the start and completion of the script.


(since the file in my example is 5 days old, the field "Log files with errors" lists d:\robocopy.log. As a result, the health state of my machine changes to warning.
If you open the health explorer for the computer, then you should see the monitor listed and enabled. If you go to the state change events view, you can see all of the parameters that were passed back as part of the property bag. The NrOfDaysAgo1 field indicates 5, which triggered the warning in my example.

If the monitor indicates that there was a problem with the log file, then you’ll get the following message in OpsMgr:

If you click ‘View additional knowledge" and open the Alert Context tabsheet, you’ll see all of the variables as well :

If the problem gets solved, the state should return to healthy automatically (depending on how you’ve set up the alerting section of this monitor)
© 2008 – 2017, Peter Van Eeckhoutte (corelanc0d3r). All rights reserved.
Similar/Related posts:
 Monitor file age with Operations Manager 2007 (vbscript monitor)
Monitoring disk space utilization growth/increase with Operations Manager 2007
Using custom/non-Performance Counter data to build graphs in Operations Manager 2007
Monitoring modems with OpsMgr 2007
Monitoring Juniper/Netscreen firewalls with Ops Mgr 2007 (using snmp and syslog)
Monitor file age with Operations Manager 2007 (vbscript monitor)
Monitoring disk space utilization growth/increase with Operations Manager 2007
Using custom/non-Performance Counter data to build graphs in Operations Manager 2007
Monitoring modems with OpsMgr 2007
Monitoring Juniper/Netscreen firewalls with Ops Mgr 2007 (using snmp and syslog)
Donate

Your donation will help funding server hosting.
